This post was organically written, non-AI farmed
A couple of years ago, I posted a review on an AI conference’s papers. I’ve been playing with Claude Opus 4.6 at work for some time now, and while I still stand by my statement, I do have some opinions on the real productivity gains to be made here.
TL;DR: It’s cool, and helpful, and a bandwidth maximizer, but not a panacea
A Learning Accelerator
I was a TA in my university’s processor design course, ECE411.
One reason I was a TA as an undergrad, apart probably from desperation on our professor’s part, was because we had gotten second place in our class’s competition and he was impressed that we had managed to do a dual-issue design that worked in 2 months. I personally am a bit proud of it. Below is our team’s design.
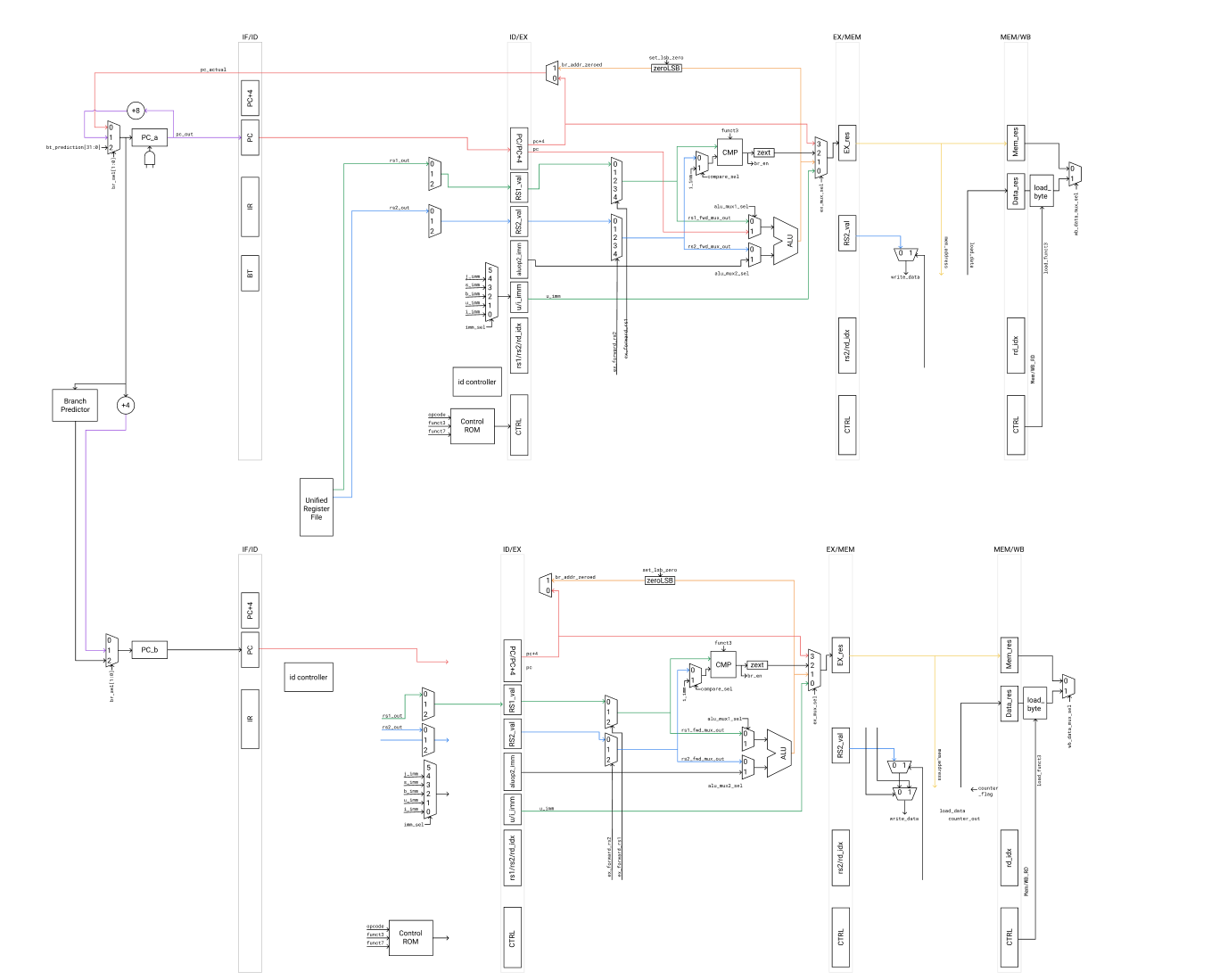
I asked my other nerdy hardware friend, half as a joke, what time period of CPU would this design fit into. Probably the late 90’s, he responded.
I reflected for a bit. Although we really weren’t doing anything novel, I was indeed surprised and marveled a bit at the condensation of knowledge that previously might have took decades for incredibly smart people to learn and iterate on, into something that two college undergrads could crank out in two months.
I think AI can, and has, accelerate one’s exploration of an area, not unlike the course at UIUC that condenses decades of CPU knowledge into a semester, but I don’t really think that will directly translate into unlocked economic value. It is an incredible interpolater, but a horrid extrapolater. It treads old ground, incredibly quickly.
That’s not to say there’s value in relearning the lessons of the past. There is! But, the minute an invention is created, the clock starts ticking on its value. That’s the basic tenent of patents and IP, that after a certain amount of time, human knowledge must belong to everybody.
In some sense, AI stands to do just that. Disseminate the cost of reaching that boundary lower than ever before. Make everybody the same. But, to get value, to push that boundary, you must be different.

Image adapted from Matt Might in The Illustrated Guide to a Ph.D.
Verification Must Find Bugs
The nature of verification is often incredibly multi-hatted. You think like a designer, for you must abstract obscure edge cases. You think like a DevOps engineer, for you must somehow schedule millions of instructions in 1000 tests on a 10 license budget. You think like a scripter, for you must mangle together the often obscure APIs that EDA tooling offers you. You must think like a data scientist, for you must analyze coverage statistics to drive better tests.
The reality of this cross-functional work is that you are, at some level, a generalist. And for decades, that has always been the skillset of a verification engineer– to juggle multiple hats, and to learn new fields quickly. The level of software rigor and number of hacks would truly astound my normal software engineer friends, but in some sense, this doesn’t matter, because the core work of a verif engineer is to find bugs. Not to worry about WNS paths or power (though those are Verif subcareers in themselves); not to worry about robust error handling (unless it impacts test generation); not to make stylistic, readable Python-ic code; not to create beautiful data visualizations. Find bugs, and just be good enough at the rest.
For decades, because that skillset necessitates so much breadth, the conventional wisdom has been that for every 1 RTL engineer we have 2 verification engineers. Perhaps one to focus on core feature development, and one to add tooling for the infrastructure needed to support new tests, models, etc.
But LLMs, however, are expert generalists. They are good enough. Truly a gamechanger for the tedium of glue logic that used to necessitate headcount; so much so that in recent years, it really feels like the ratio of RTL:Verification has been more like 1:1.5 or 1:1, and there’s been an explosion of CPU and hardware startups as a result. I say nothing about the effectiveness of this paradigm, just that verification teams in hardware startups across the industry are running much leaner than what I am used to. The tools and bespokeness that a collective 100 people’s usescases might have necessitated a small “tooling and infrastructure team” are not as necessary if each person can write their own shoddy wrapper.
What I can say is that, personally, I have been using Claude quite a lot at work. I have found that AI, more than any other thing, exemplifies the Pareto principle the most. Some things are amazingly one-shottable, things that I’ve spent months on-and-off doing, though many more are not.
AI Is Boring, Generic, and Average, But Sometimes That’s What You Want
This author writes about the commodification of software, and while he has a point, and also provides insight that does scare the young starry-eyed technologist in me, I do see the potential and, in some sense, a need for the “IKEA-ification” of software.
Oftentimes, you want average and boring.
Consider coverage.
Not, mind you, the writing of coverage, which I cannot yet trust an AI to analyze, but the raw digestion and parsing of all of the cruft that a coverage database entails.
This is 1500 pages of a “VCS User Guide” from Synopsys (which, by the way, is one of 20 different docs). This is from 2015, and has only gotten bigger. It contains all the performance flags, guides to run simulation, ways to interact with the design, etc. Traditionally, it might be a very small sub-team’s entire job to maintain the general verification team’s usage of the wrapper scripts, build flows, coverage collectors, etc. For those that maintain different EDA providers, this effort can be doubled or tripled.
The coverage collection mechanisms, and all the coverage CLI tools, across all vendors, are often obtuse, poorly documented, and 20% of the time straight up don’t do the function they advertise, with output that is not standardized.
The coverage collection and the regression runner can be thrown in a loop, simply told “please collect this data into a JSON for me once it finishes”, and thrown onto a regression dashboard to track over time. This can, and has been done, in 1 day.
Or, consider this very website. I will be quite honest and say that I don’t care much about it. I use Hugo, on S3, with some random website themes. If I could’ve used AI to set up my website, I would’ve done it.
It’s not beautiful, it’s a bit hacky, and is missing a lot of polish, and probably uses a horribly insecure pickling method, but who cares? It’s good enough.
But the core task of a verif engineer is not to stare at coverage data, or build regression dashboards. It is to find bugs. It is to– yes, stare at coverage data, which, yes, would take an AI a couple of minutes or if not an AI, a script that would have taken a Tooling and Infrastructure team perahps a week and thereby the usage of AI indirectly had this cost savings– to think and extrapolate: What else?
If “Average” Is Easier Than Ever, Then “Exceptional” Becomes More Important Than Ever
The beauty/Sisyphean nature of capitalism is that our standards, and thus what we will pay top dollar for, are constantly changing. Capitalism, in some sense, provides a mechanism for those who truly have a niche to provide value. It is the unlikely things, the tail events, that create an outsized effect.
AI, by the very nature of its design, will only ever do what is “most likely”.
Consider coverage again. This time, the development of a testplan. If one were to lazily throw the documentation and a codebase through an agent and ask it, “Please identify coverpoints across the documentation and the spec”, it will often come up with verbose, redundant, and tautological statements. Line and toggle coverage, for instance, is not terribly useful in mature projects. The existence of a misprediction is not terribly interesting.
Perhaps the number of mispredictions, on a specific feature, given a specific cycle, for a specific simultaneous event, is more interesting. To consider a chain like that requires much deeper thought, an intuition of the design, and several people to review that something makes sense and is valuable.
There will always be bugs to be found. Depending on the extent of a “Ground Up” design, it is not ridiculous to say there could be hundreds of thousands of bugs. The question is, how can we find “showstopper” bugs– ones that catch fire, or fully hang a CPU– in 2 or 3 years, because it seems that that’s what market forces have dictated as an acceptable time period for the hardware development lifecycle.
90% of these might be “easy” bugs. I have full confidence AI could find 90%, without much augmentation.
A further 9% might be found with expert direction. And, then, a further 0.9% that may be found as ECOs.
It is the 0.01%, the 1 or 2 bugs in the hundreds of thousands that may sometimes light your CPU on fire, a monstrous interwoven chain of 5 different features and 20 simultaneous events. Or, really, it doesn’t even need to be that extreme. It could be a CPU sleep-wake bug that completely subverts any power modeling you had imagined, and makes your CPU so badly uncompetitive with the timing of the market and the sunk capital expenditures that it nearly kills the company and gets a board of directors calling for blood.
AI cannot solve this, because there have always been bug escapes. It is a problem of focus and cross-communication.
I think, in a world where generating bad code is as easy as ever, using AI to verify this existing slop is not really the hard problem. If anything, it just becomes necessary, in a sort of arms race against continued bloat of code, while simultaneously still insufficient. The hard problem of finding this 0.01% hasn’t really gone away. Once it is found, yes, perhaps AI can help execute, but how can it be found in the first place?
To Develop Taste, Be Unsure
I have, funny enough, found AI to be horrendous for debug.
It doesn’t hurt, certainly. On the extreme end, it can be a waste of time to parse through false positives. But very easy bugs that require perhaps only 1 layer of driver investigation, and perhaps 10 minutes of my time, have some non-zero value when used with AI.
But even with Opus 4.6, I haven’t found much progress in finding bigger root causes. It is bad at deciding under uncertainty, and describing what is it uncertain about. “How can I be more certain” is a question of taste.
Even beyond this, I have largely stopped debugging with AI. Debugs provide data into one’s process, and I find it dangerous to offload everything to an LLM, for, again, AI is exceedingly average, and to be a verif engineer requires some unique insights. And to generate these unique insights, you need to have a taste for the very word, “unique”.
The thing is, there is so much weight in each of those words– “verbose”, “redundant”, “unique– that can only have been built up after a couple of years of studying complex designs so as to intuit not only “what is necessary”, but “what is excessive”, and “what is enough”. A standard of taste.
Many people will have a version of an “Impossible Backhand”; that is, something that an amateur will easily miss, but an expert will catch. It is the marginal gains on top of a mountain of experience that really determines the value. It is the internalization of a model of what should happen, and how a verif engineer can extrapolate off of this uncertainty.
It is on the resolution of this uncertainty, the eadjustment of one’s expectations vs. the reality of new incoming data that provides growth, and development of taste.
This, some may argue, is the reason for a “human-in-the-loop” system, so that one can architect and instill the impression of taste in a binary-search manner, but I have found that to review code also requires understanding it. Even if an AI were able to come up with a complex chain as above, you must still verify that it is correct, and to verify requires understanding. I also am not convinced that, especially in the world of hardware, where IP secrecy is King, we can develop the proper stochastic weights of the N*K different associations and interleavings that a feature’s complexity may add to a CPU.
“Just have a bigger context window” helps, but is a fundmental limitation that feels downplayed oftentimes. Jevon’s Paradox has been tossed around a lot these days. See again my rant on uniqueness. Also, could you really have a context window that lasts across different companies, and projects, and decades?
Yes. That’s called a human.
I’m not sure how to end this, but do shoot me an email please! I think about AI taking my job a lot. This is pure coping, but I think it’s useful, but not that useful.
There’s a small part of me that thinks, if I went to college just a few years later, it’d be real tough to make it in this industry. I hope there’s some sympathy for the younger engineers. We need to foster their growth.